A linguistic introduction to d3.js
Originally published on: Medium
How to go from a tentative to a confident user
d3.js is a fantastic library — but I can honestly tell you that for a long time I used it without fully understanding it. Lacking any solid mental model of what I was working with, I would admittedly tend to copy/paste pieces of code from various snippets over at ObservableHQ, cross my fingers and hope for the best.
This article is not intended to serve as a comprehensive introduction to d3. It is merely intended as an exposition of its top-level concepts, enough to set you on your way to becoming ‘expressive’ rather than ‘tentative’ with it.
The API documentation is intimidatingly huge, but there is a subset of it that lays a crucial foundation for reading and writing programs that use d3. My intention here is to communicate those foundations in a way that I would have liked to have had them communicated to me when I was starting out, and have you using it confidently rather than hesitantly.
Let’s do this!
Nouns and verbs
Whenever I am trying to understand a system, I often ask myself “what is the system aiming to do, and what are the nouns, and what are the verbs that I can use to describe it in plain English”? If you have had any experience with d3 before, you would know that a typical program looks something like this:
Code Snippet One
<!DOCTYPE html>
<meta charset="utf-8" />
<body>
<script src="https://d3js.org/d3.v5.min.js"></script>
<script>
const data = [3, 5, 7, 2, 9, 2, 10, 4, 9, 3]
const height = 500
const width = 200
const barWidth = width / data.length
const yScale = d3
.scaleLinear()
.domain([0, d3.max(data)])
.range([0, height])
const svg = d3
.select('body')
.style('text-align', 'center')
.append('svg')
.style('border', '1px solid black')
.attr('width', 200)
.attr('height', height)
const bars = svg
.selectAll('rect')
.data(data)
.join('rect')
.attr('height', (d) => yScale(d))
.attr('width', barWidth)
.attr('x', (d, i) => i * barWidth)
.attr('y', (d) => height - yScale(d))
.attr('stroke', 'white')
.attr('fill', 'steelblue')
</script>
</body>
See here to see what this code results in. It won’t win any dataviz awards anytime soon, but the aim is to be sufficiently stripped down to guide this discussion. The code may make varying levels of sense depending on your experience — if you are completely new to d3 it may make no sense at all.
By analysing this code block in terms of the nouns and verbs at play here — making the implicit more explicit — I hope that it will make more sense to everyone with a basic understanding of Javascript and SVG. But there is a question we should turn to first of all — what is the aim? What is the above code trying to achieve?
The ‘aim’
D3 stands for ‘data driven documents’, and as such, the aim is to produce a document that is driven by data (duh). I suppose that is the aim of all data visualisation — to set up a mapping between some data and some presentational elements that can be seen and possibly interacted with. If the data were to change, we would expect some aspect of the visual experience to change — it is a mapping.
When it comes to web documents, the ‘presentational elements’ take the form of nodes. In case you have forgotten what a node is, open up developer tools and run document.querySelectorAll(‘div’) to see all the <div/> nodes that make up this current page.
d3 fulfills the dataviz philosophy of mapping data to nodes, by taking the (perhaps obvious) approach of storing the data points as properties on the nodes themselves. To show this, try opening this link, and running document.querySelectorAll(‘rect’) in developer tools. What you should see is an array of 10 <rect> nodes (one for each of the elements in the data array, featured in the code). If you expand one of them to observe its attributes, you should see all the various attributes that are typical of an SVG node. But there is a crucial addition. Down at the bottom, lies the ___data___ property:
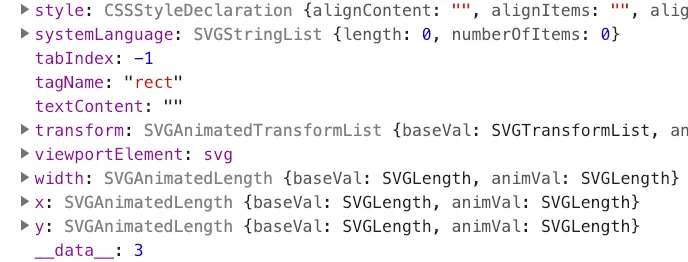
For this particular <rect>, the first one in the list, the property takes the value of 3, which also happens to be the first value in our data array. Here we get to the first ‘principle’ of d3, that much of your work will involve binding data to nodes in the form of a ___data___ attribute on the node itself. You may not be aware that this is what you are doing, since the d3 API hides such details from you. But ‘under the hood’, this is what you are doing.
Much of your work in d3 will (inadvertently) involve binding data to nodes in the form of a ___data___ attribute on the node itself
Once data is successfully bound to a node, it then becomes possible to style the node on the basis of that data. Every time you see .attr(key, value) in the code above, view it as an attempt to change the appearance of nodes. For example, the call to .attr(“height”, d => yScale(d)) is assigning the ‘height’ property with, not a fixed value, but a value that is a function of the ___data___ that is bound to that node. Our nodes are data-dependent in the sense that we have a set of nodes, one for each data point, with a height that corresponds to the value of that data-point. In other words, we have ourselves a ‘data driven document’.
The other sense in which the document is ‘data driven’, is the very fact that we seem to have created a <rect> node for every element in the data array. If there were only 7 elements in the array, the program would only create 7 <rect> nodes. If there were 12 elements in the array, the program would create 12 <rect> nodes, and so on. Given that we have aimed to setup a mapping between data points and <rect> nodes, we want to ensure that we have the same number of data points as we have <rect> nodes.
Imagine that for some reason there were already 50 <rect> nodes in the document at the time the d3 program is run. Given that we aim to map a <rect> node to each of our 10 data points, it means that 40 of these currently-existing nodes are now redundant, doesn’t it? Wouldn’t it make sense to delete these 40 nodes, since they no longer represent the state of our data?
Such a case would occur if we were to run our program multiple times with different numbers of data points. Perhaps our program is hooked up to some ‘live data’, such that the length of the data array changes over time. Our program would need to somehow ensure that the number of <rect> nodes on the page matches the length of the data array. If you sometimes find D3 unnecessarily complex and hard to understand, bear in mind that it is designed to handle such a use-case. It is also what makes d3 so powerful — we are not just aiming to setup a mapping, we are aiming to setup a dynamic mapping that can respond appropriately to changes in the data.
The d3 API is designed to allow you to setup a dynamic mapping between data and visual elements, that can respond appropriately to changes in the data over time
Therefore, in addition to the assignment of data points to nodes, the ability to create and delete nodes themselves, as and when it is necessary, is another use-case that d3 is designed to deal with.
Now that we have the broad aims out of the way (1) creation/deletion of nodes based on data (2) assigning data values to nodes and (3) styling nodes on the basis of those data values, let us return to nouns and verbs.
‘Three aims’ of d3:
1. creation/deletion of nodes based on data
2. assigning data values to nodes
3. styling nodes on the basis of those data values
Nouns + Verbs
We need to add some new terms to our vocabulary if we are going to make sense of Code Snippet One.
1: Selection (noun)
Firstly, I want you to adopt the term selection.
When you look at any d3 code, the first thing you might notice is that there is a lot of chaining going on. Chains like this are possible in Javascript whenever the return value of a method has methods of its own. For example, you might have seen chains of promises like these:
getData()
.then((data) => {
return 'hello'
})
.then((data) => {
return data + ' world'
})
… which are possible because each call to .then itself returns a promise, which has its own .then method that can be called, and so on. What is implicit in this code is that ‘promises are being passed around’.
Which raises the question, what is being ‘passed around’ in a chain of d3 statements? The answer, in most cases, is a selection. You can start by thinking of a selection as similar to the result of calling document.querySelectorAll(), in the sense that it represents a collection of nodes. But it is a slightly more complex data structure than a simple array, as we shall see.
A ‘chain of selections’ usually begins with a call to d3.select or d3.selectAll. For example, you could navigate back to this page, and call d3.selectAll(‘rect’) in developer tools, just as you called the native document.querySelectorAll(‘rect’) before. If you probe around the resulting data structure, you will see that the list of nodes is to be found under the _groups property. Don’t get hung up on this data structure for now, just see it as a collection of nodes that exposes a handy set of methods for manipulating all of those nodes in a single call.
Think of a ‘selection’ as a collection of nodes that exposes a handy set of methods for manipulating all of those nodes in a single call
Having obtained a selection , we are in ‘d3-land’. A selection has numerous methods available on it, which, when called, can themselves return selections. e.g. look at this section from Code Snippet 1:
Code Snippet Two
const svg = d3
.select('body')
.style('text-align', 'center')
.append('svg')
.style('border', '1px solid black')
.attr('width', 200)
.attr('height', height)
The chain of selections is ‘kicked off’ by a call to d3.select(), which gives us a selection, which has among its methods, .style, .append and .attr and when any of these are called it returns a selection that itself can call .style, .append and .attr (among other things). This explains why chains are so prevalent in d3. Just as promises have methods that can return promises, selections have methods that can return selections.
By calling a method on a selection, you are essentially saying ‘do something for every node in this selection’. Among the methods available on a selection, is the .select method. This is potentially confusing (it was for me). Whenever you see a call to .select() in some d3 code, it is worth making a deliberate note of whether it refers to d3.select or whether it refers to the .select method being called on an existing selection (i.e. selection.select) . In the former case, we are selecting a node. In the latter case, we are selecting a descendant node for every node in the current selection, so that the nodes in the current selection are being ‘mapped’ in a 1:1 fashion to a set of new ones. I wanted to raise this distinction now because you will run into it at some point.
A key part to understanding what a line of d3 code is doing at a particular point in time is to ask yourself what is the current state of the selection? Can you figure out what nodes have been selected and are currently being operated on? Let’s do this exercise with Code Snippet Two.
- Firstly, we have d3.select(‘body’). This gives us a selection that contains a single node, which happens to be the
<body>node that is already present on the document before the javascript code begins its execution. - Next, we call .style(“text-align”, “center”) which serves to mutate a presentational aspect of this node. If there happened to be more than one node in the selection at this point, each node would be mutated in this way. The result is the same selection as before (a single
<body>node) - Next we call .append(“svg”). This also mutates the
<body>node, in the sense that it appends an<svg>node onto it as a new child. This time, however, instead of returning the original selection (the one from line 1), it returns a new selection consisting of the newly-appended<svg>node. In fact selection.append serves to append a new node, and then call selection.select to select it (it is a ‘wrapper’ around selection.select) - The following three method calls, .style(“border”, “1px solid black”), .attr(“width”, 200) and .attr(“height”, height) all serve to stylistically mutate the node/s in the current selection (remember in this case it currently consists of a single
<svg>node) , and return the same selection that it acted on.
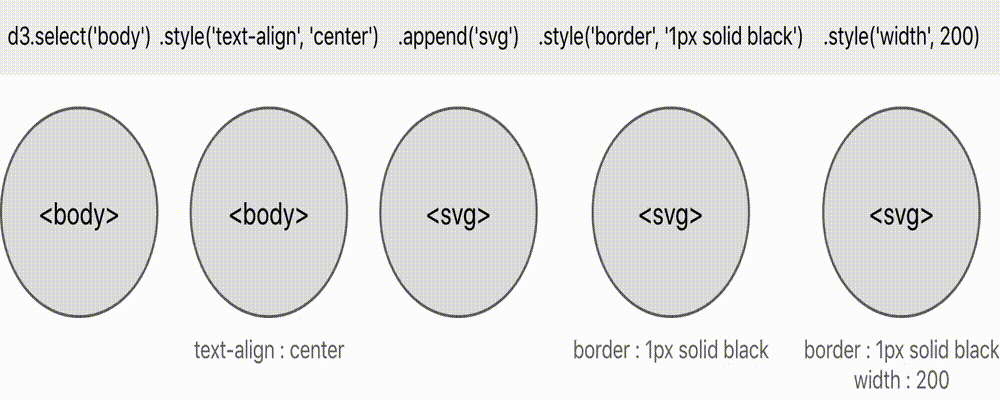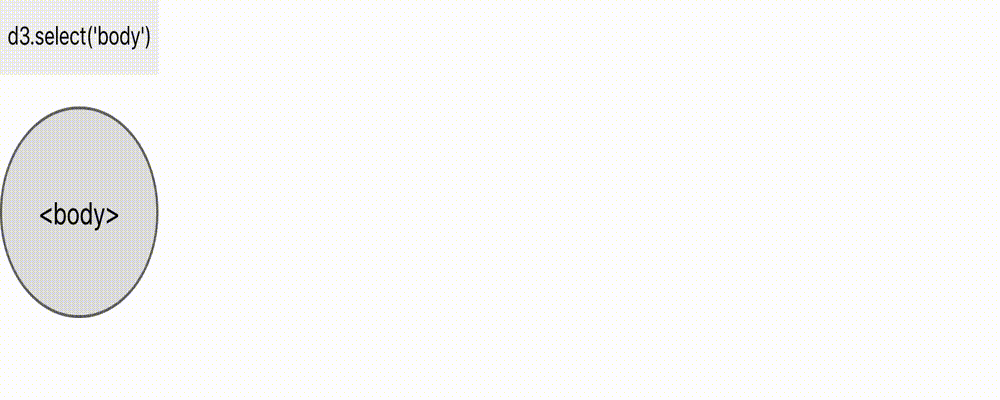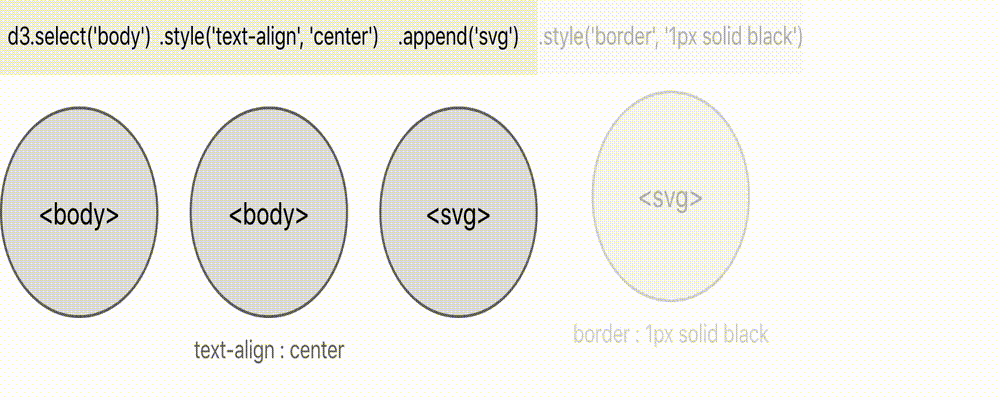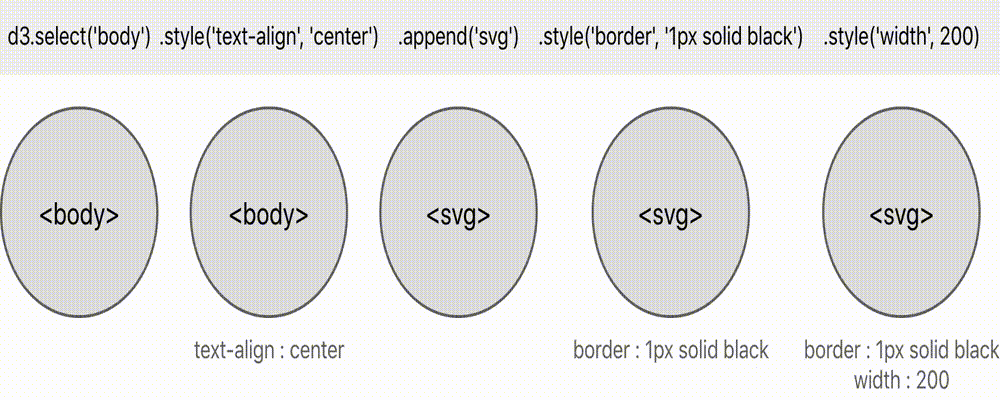 The grey ovals represent the ‘current selection’ at that point in the chain
The grey ovals represent the ‘current selection’ at that point in the chain
It should therefore be apparent to you that the methods available on a selection can be divided into those that serve to mutate or change the appearance of nodes in the current selection (e.g. selection.attr), those that can update what the current selection is referring to (e.g. selection.select), and those that do both (e.g. selection.append). (I was thinking of adopting the terms cosmetic updates and selective updates as a way to cement the distinction between these cases, perhaps you can come up with some better ones yourself.)
 Note: This is not an exhaustive list of selection methods
Note: This is not an exhaustive list of selection methods
This, in my opinion, also explains why d3 can have such a steep learning curve. Certain methods, like selection.append can serve to ‘silently’ update what the current selection refers to, and unless you have come to expect this, you may find yourself unpleasantly surprised. It is worth your time, when learning new methods that a selection makes available to you, to ask yourself whether it serves to update the selection(i.e. whether the selection refers to the same set of nodes as before) or whether its effect is limited to the nodes themselves.
So by now you should have grasped that making a selection is D3’s way of referring to collections of nodes, so that once a selection is made, it is possible to manipulate the stylistic attributes of the nodes it contains. Code Snippet Two can be summarised in plain English as ‘select the body node and update its style’.
Next, I want to introduce Code Snippet Three:
const bars = svg
.selectAll('rect')
.data(data)
.join('rect')
.attr('height', (d) => yScale(d))
.attr('width', barWidth)
.attr('x', (d, i) => i * barWidth)
.attr('y', (d) => height - yScale(d))
.attr('stroke', 'white')
.attr('fill', 'steelblue')
Code Snippet Three
At first glance, this may look similar to Code Snippet Two, but in fact it requires you to add a few more nouns to your vocabulary in order to fully understand it.
Let’s look at the first bit, svg.selectAll(‘rect’):
svg is the label we gave to the selection that results from the final line of Code Block Two (don’t go thinking it’s some global variable). In other words, it is the selection that contains the <svg> node that we appended to the <body> node.
Remember how we stressed that selection.select(‘x’) was distinct from d3.select(‘x’) and that it meant ‘for every node in this selection, select the first descendant node that matches x’ ? Well, selection.selectAll can roughly be interpreted as ‘for every node in this current selection, select every descendant node that matches x’. Therefore, svg.selectAll(‘rect’) can be interpreted to mean ‘select every rect element that descends from our <svg> node’.
Let’s summarise these distinctions:
d3.select(x) = give me a selection that contains the first node in the document that matches x
d3.selectAll(x) = give me a selection that contains all the nodes in the document that match x
selection.select(x) = for every node in the current selection, give me the first descendant node that matches x (1:1 mapping)
selection.selectAll(x) = for every node in the current selection, give me all descendent nodes that match x (1: many mapping)
So, the first part of Code Snippet Three serves to ‘select every rect element that descends from our <svg> node’. At this point an astute reader might be wondering:
“But there aren’t any rect elements? So far we just have a body node with an
<svg>node appended to it?”
Assuming that this code is running for the first time on a blank document, such a response would be correct. The selection that results from calling svg.selectAll(‘rect’) would be an empty selection.
Okay, so now we have an empty selection and the next step calls .data(data) on it. What sort of an operation is this? Does it update the selection or does it mutate the nodes? The answer is kind of both. If the current selection were to actually have some nodes in it, it would update them in the sense that it serves to go ‘assign the _i_th data point as the ___data___ attribute on the _i_th node in the current selection’. In this sense, it would accomplish the second ‘broad aim’ of d3, namely the assignment of data values to nodes.
It is also a ‘selective update’, in a sense. It is still the same selection in the sense that it is still an empty selection. And if we had called .data(data) on a selection of 10 <rect> nodes, then we would still be left with a selection of 10 <rect> nodes. But something has changed. We are left with a type of selection that I believe deserves its own noun. Whenever we call .data() on a selection, it results in a binding.
2: Binding (noun)
In order to prove to yourself that the nature of a selection changes once you call .data() on it, try the following:
- Visit this link (it is the same as Code Snippet One, just that I have added a couple of console logs to inspect the nature of the selection before and after the call to .data())
- Open up developer tools to see the logs
- Probe the differences between the two log statements
The first thing you should notice is that the selection now has two additional keys: _enter and _exit. So I think we can agree that while we are still dealing with a selection, it is not quite the selection it once was. It is now a binding.
What does _enter and _exit refer to? Remember the first ‘aim’ of d3? It was the creation/deletion of nodes based on data.
- When we first run a d3 program in a blank document, usually we have fewer nodes than data points, so that if we want to map nodes to data points, then we must create some.
- If it is not the first time we have run the program in a document (if, for example, our program is hooked up to some ‘live’ data that is regularly updating), and we have fewer data points than before, then it will likely mean that we now have more nodes in the document than we need. In this case it will be necessary to delete some of the now-redundant nodes that we created previously.
Let’s focus on the specific case in hand, in which we seek to map each data point in our data array onto a <rect> node in the document. We need some way to represent each of three cases (assuming that the data array may be subject to change over time):
- A node that we need to create, because a particular data point has not yet been mapped onto a node in the document
- A node that we need to remove, because its associated data point has been removed, and along with it must go the associated node
- A node that we need to update, because its associated data point has been updated
After having passed our data array (it always needs to be an array type) to the selection of nodes that we wish to map to it by going selection.data(data), d3 has all the information it needs to sort the the current node selection into the above three cases. d3 uses the terms, enter, exit and update to refer to these three cases, respectively. Since a selection is d3’s term for a collection of nodes, we refer to a collection of nodes that fall under case 1 as being the enter selection, a collection of nodes that fall under case 2 as the exit selection, and the collection of nodes that fall under case 3 as the update selection. Here’s a diagram that I have shamelessly lifted straight from Mike Bostock, the creator of d3's, site:
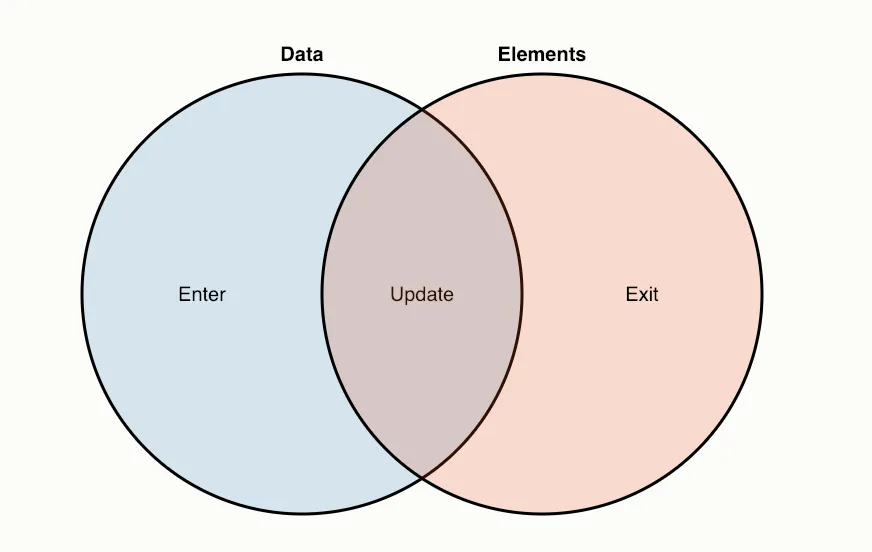 A ‘binding’ is a special selection that provides methods that allow access to three selections that map to the three cases above
A ‘binding’ is a special selection that provides methods that allow access to three selections that map to the three cases above
3. ‘Pseudo-nodes’ (noun)
An astute reader will recognise at this point that the enter selection represents a selection of nodes that are yet to actually exist.
It is worth dwelling on this point for a second, because it gets right to the heart of what people often find difficult to grasp when they are learning d3. ‘A collection of nodes that don’t yet exist’ is a difficult one to get your head around. If you think of it as a ‘collection of pseudo-nodes’ then that might help. In any case, it will be necessary at this point for us to update our definition of a selection as ‘a collection of nodes, whether they actually exist in the document or not’.
Users of React or other ‘Virtual DOM’ libraries might find this concept natural, to represent nodes as javascript objects before they are actually created. A selection is similar, in this case. In contrast, the update and exit selections, by definition, will always refer to nodes that already currently exist in the document.
So let’s review where we are at. By calling svg.selectAll(“rect”).data(data) for the first time, we end up with a binding, with references to:
- an enter selection that consists of 10 as-yet-uncreated nodes corresponding to the 10 elements of data. The type of these nodes (i.e. whether they are
<rect>s, or whether they are something else like<circle>s) has yet to be specified. This selection is obtained by calling .enter(). - an exit selection that is empty. The document had no
<rect>nodes to start with — svg.selectAll(‘rect’) returned an empty selection — so there was no chance of this selection including any redundant<rect>nodes. This selection is obtained by calling .exit(). - an update selection that is empty. Again, since the document had no
<rect>nodes to start with, there are none that require updating with new data either. This selection is what is returned to you by default — you don’t need to call any additional methods to select it.
So a binding is simply a selection, consisting of our update nodes, and featuring some special methods that give us access to the enter and exit selections. Hence, you may come across patterns like this:
const newBars = svg.selectAll('rect').data(data).enter().append('rect')
This can be interpreted to mean, in plain English: “select any existing <rect> nodes that descend from our <svg> node, and set the ___data___ attribute of the _i_th rect element with the _i_th data point in _data_. For any data point that lacks an associated node, create a new <rect> element to represent it”. Let’s expand on this briefly.
We learned earlier that selection.append serves to both mutate the nodes in a selection (by appending a new node to them) and return the newly appended nodes in the form of a fresh new selection. In this case, the call to .append(‘rect’) says “for each of the pseudo-nodes in our enter selection, append a <rect>, and return this fresh new selection of <rect>s.
4. Propagate (verb)
In the previous example, the _i_th <rect> node will end up storing the _i_th data point as its ___data___ attribute. This result is not actually obvious, and is worthing highlighting explicitly. We should expand our definition of selection.select as ‘for every node in this selection, select the first descendant node that matches x and propagate data to it’.
As we mentioned before, the .append method is actually a wrapper around .select, and so .append has this property as well. In the case above, it serves to create a <rect> node for every one of our pseudonodes (each of which, if you remember, had ___data___ bound to them), propagate the data points along to the newly created ‘real’ nodes in a 1:1 fashion, and then return these newly created nodes in a new selection. (note that _selection.selectAll_ does not have this data-propagation property — perhaps it is because there is no such 1:1 mapping to the newly-selected nodes and so it’s not easy to tell which data should go where).
selection.select has the side-effect of propagating data to the newly selected nodes, so that they have the same __data__ attribute as the node they were selected from. selection.selectAll does NOT have this property
Any additional method calls that may be chained on the end, will serve to operate on these new <rect> nodes. Maybe you will want to give them a size, a position, or a colour. In the case below, we will give them a height that is dependent on their ___data___:
const newBars = svg
.selectAll('rect')
.data(data)
.enter()
.append('rect')
.attr('height', (d) => yScale(d))
enterwithStyling.js
If the call to svg.selectAll(‘rect’) had returned some nodes, (i.e., not an empty selection), then the subsequent call to .data(data) would have updated some of them with new data. By this I mean, their ___data___ attribute would have been reassigned to some new value. But this would be imperceptible to a user unless we perform a data-driven cosmetic transformation to these nodes.
Since the binding is itself a selection of these ‘updated’ nodes, we just need to call some cosmetic methods on it in order to make the new data visible. For example:
const updatedBars = svg
.selectAll('rect')
.data(data)
.attr('height', (d) => yScale(d))
visibleUpdate.js
Much of the d3 examples you will see online tend to only make references to the enter selection. If your intention is to create a visual representation of some static data (i.e., assuming that the data array will never change), then something like enterWithStyling.js (the code snippet two blocks above), which only works with the enter selection, will suffice. By operating on the update and exit selections as well, you are setting up a dynamic mapping, that will be responsive to updates in the data.
There are at least two ways of combining enterWithStyling.js and visibleUpdate.js (i.e. to both create and style the <rect> nodes ‘from scratch’ and to update them when the data changes). The ‘old’ way is to do this:
const binding = svg.selectAll('rect').data(data)
binding
.enter()
.append('rect')
.merge(binding)
.attr('height', (d) => yScale(d))
merged.js
Here we save a reference to the binding, which is in effect an update selection, and from it, we obtain the enter selection (which we use to create <rect> nodes from scratch), and then merge it (think of it like a union of sets, if you are mathematically inclined) back with update selection. If we ask ourselves ‘what is the selection referring to’ after the ‘merge’ operation, we can say that it refers to ‘newly created rect nodes, along with the nodes that were already there in the first place’.
Now that the selection is referring to this combination of cases, we can style this selection of nodes in one fell swoop using selection.attr. See here for an example of this occurring (I setup a ‘dynamic’ dataset in order to show the value of doing things this way).
You might have noticed that the code makes no reference to the exit selection. Indeed, when you look at the example, you can see that over time, the number of <rect> nodes on the page never decreases, even though sometimes it should, in cases when the data array shortens in length. Let’s fix that by making reference to the exit selection:
const binding = svg.selectAll('rect').data(data)
binding
.enter()
.append('rect')
.merge(binding)
.attr('height', (d) => yScale(d))
binding.exit().remove()
fullUpdatePattern.js
Each selection has a .remove method available on it, which serves to remove all of the containing nodes. (For current purposes, it is hard to see why one would want to remove any nodes other than the exit selection). Let’s see how that looks.
Ok, that’s better. We can now see the number of <rect> nodes on the page increasing and decreasing in tandem with the length of the data array. We finally have ourselves a ‘dynamic mapping’.
Newer releases of d3 introduce a new selection method, called selection.join which makes this whole process a lot easier and with less ‘boilerplate’. You might recognise this method from Code Snippet One. With it, we can rewrite the previous example like this:
const bars = svg
.selectAll('rect')
.data(data)
.join('rect')
.attr('height', (d) => yScale(d))
join.js
selection.join will append the specified element to each of the ‘pseudo-nodes’ in the enter selection, and it will return you these new nodes and the updated nodes (if any) in a single selection, so that subsequent lines can be used for styling them both at the same time. It will also remove any nodes that have been made redundant by the latest data binding.
Wrapping up
If you’ve made it this far, it means you have all the mental models and terminology necessary to understand Code Snippet One. The only thing I haven’t covered yet is the yScale that features at the top of the code snippet, but I’m assuming you already know what a scale is. In d3, creating a scale requires writing the following ‘skeleton’:
generator().domain().range()
And you end up with a function that maps values in your dataset to an output range that usually refers to SVG coordinates. It is worth highlighting that in SVG coordinates, the y value increases as you move down the page. The diagram below should help explain why we need to set the y coordinate of each rect according to height — yScale(d) (the y coordinate refers to the position of the top edge of the <rect> node):
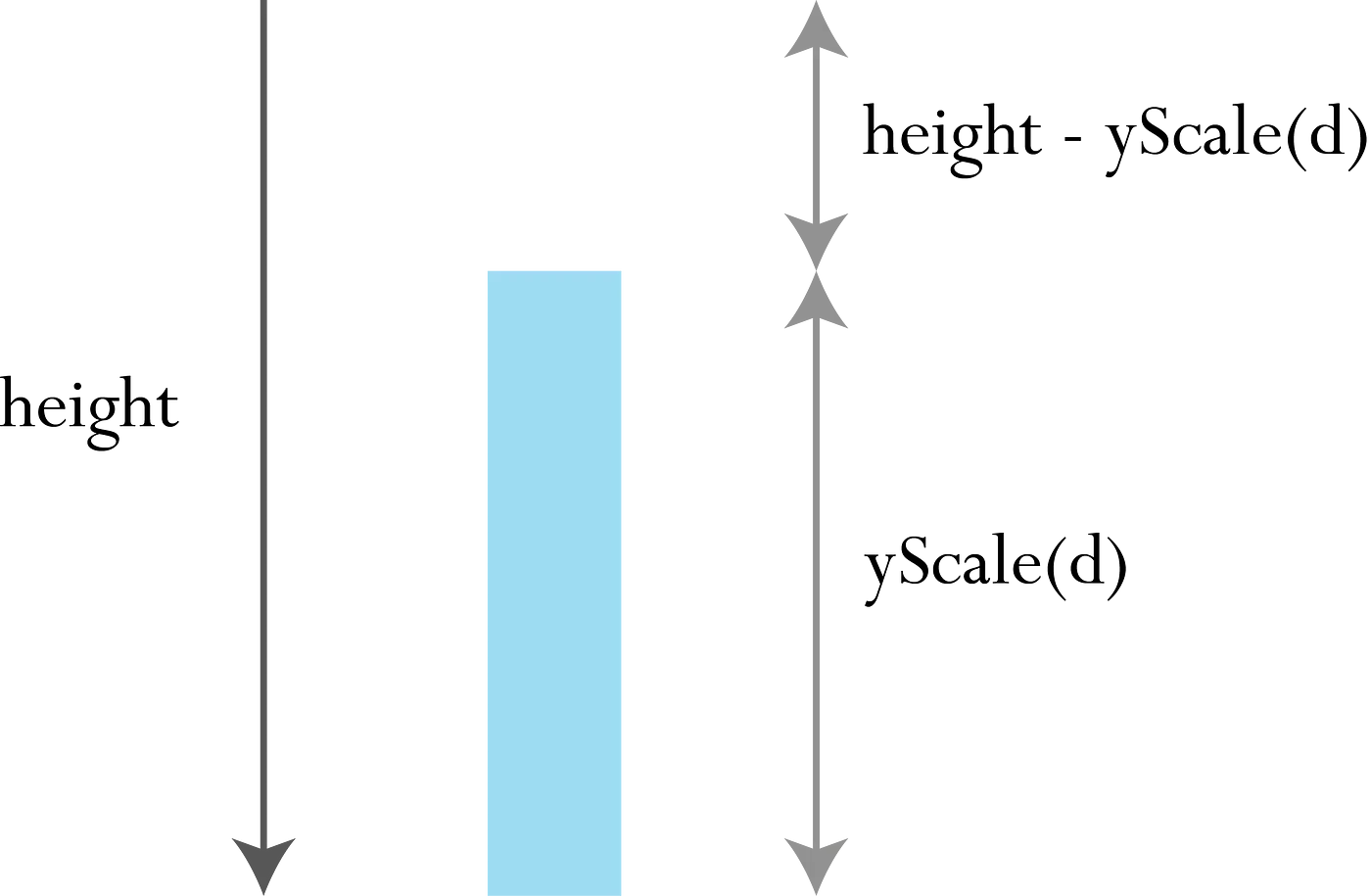
It should go without saying that d3 also provides a myriad of ‘helper’ functions like these, that make the construction of all sorts of different chart types a whole lot easier. Have fun exploring them all!
This should be enough for you to get going. You’re next ‘level up’ will involve coming to a better mental model of what a selection actually is. I still need to introduce you to another noun, called a group. This will help you come to a more sophisticated understanding of the data-binding process. If you can’t wait to find out about this, check out this article.
If this tutorial was helpful to you, please do let me know below in the comments, and I will write another article that explains selections in more depth, and perhaps plug up any leaky abstractions. Also, I would be interested to know what you think about this way of structuring a ‘how-to’ article in terms of nouns and verbs. Was it helpful?
’Till next time.